SLO Basics
In recent years, organizations have increasingly adopted Service Level Objectives, or SLOs, as a fundamental part of their Site Reliability engineering (SRE) practice. Best practices around SLOs have been pioneered by Google—the Google SRE book provides a great introduction to this concept.
In essence, SLOs are rooted in the idea that service reliability and user happiness go hand in hand. Setting concrete and measurable reliability targets helps organizations strike the right balance between product development and operational work, which ultimately results in a positive end user experience.
What is a Service Level Objective?
SLOs quantify customers’ expectations for reliability and start conversations between product and engineering on reliability goals and action plans when the goal is at risk. An example SLO for a service is 95% availability in a rolling 28-day window.
You might feel tempted to set the objective at 100%, but that’s too good to be true. Change brings instability, which will inevitably lead to failure. Not only is 100% reliability an impossible target, but it would also mean that you can’t make any changes to the service in production. So expecting perfect reliability is the same as choosing to stop any new features from reaching customers and choosing to stop competing in the market.
The rule of thumb for setting an SLO is to find the point where the customer is happy with the service’s reliability.
Who does your SLO matter to?
In order to get the main stakeholders across your organization to adopt SLOs, you will need them to agree on reliability targets that are realistically achievable, given the priorities of the business and the projects they wish to work on. We will take a closer look at what end users, developers, and operations engineers care about—and how we should factor in their goals and priorities when setting SLOs.
End Users
No matter what product, end users have expectations for the quality of service they receive. While you could use support tickets or incident pages to gauge how unhappy your customers are, you shouldn’t solely rely on them for making product decisions as they do not comprehensively capture your end user experience.
SLOs help you figure out the right balance between product innovation (which will help you provide greater value to your end users, but runs the risk of breaking things) and reliability (which will keep those users happy). Your error budgets dictate the amount of unreliability that can be afforded for development work before your end users are likely to experience a degradation in quality of service.
Developers and Operations Engineers
Traditionally, the split between developers and operations engineers stems from their opposing goals and responsibilities: developers aim to add more features to their services, while operations engineers are responsible for maintaining the stability of those services.
With SLOs—and their accompanying error budgets—in place, teams are able to objectively decide which projects or initiatives to prioritize. As long as there is an error budget remaining, developers can ship new features to improve the overall quality of the product, while operations engineers can focus more heavily on long-term reliability projects. But when the error budget begins running low, developers will need to slow down or freeze feature work—and work closely with the operations team to restabilize the system before any SLAs or SLOs are violated.
In short, error budgets act as a quantifiable method for aligning the work and goals of developers and operations engineers.
Before we go any further, let’s walk through some of the fundamental concepts and definitions we use within the product.
Key Terminology
-
SLA or Service Level Agreement is an explicit or implicit agreement between a client and service provider stipulating the client’s reliability expectations and service provider’s consequences for not meeting them.
-
SLO or Service Level Objective is an agreement within an SLA about a specific metric over a certain period of time. It is expressed as a percentage or ratio over some time, for example, “99.95% availability over 24 hours”.
-
SLI or Service Level Indicator measures compliance with an SLO (Service Level Objective). So, for example, if an SLA specifies that your system will be available 99.95% of the time, your SLO is likely 99.95% uptime and your SLI is the actual measurement of your uptime. Maybe it’s 99.90%, or maybe it’s 99.99%.
-
Error Budget is the maximum acceptable downtime without breaching the SLO. For example, if your Service Level Agreement (SLA) specifies an uptime of 99.99% (in a year) before the business has to compensate clients for the outage, that means your error budget (or the time for which your system can go down without any consequences) is 52 mins 35 secs in a year.
-
Burn Rate tells you how fast you are consuming the allocated error budget.
SLOs can be defined over various time intervals, you can either use a Rolling Time Window or a Fixed Duration Window.
-
Fixed Duration, when selected as the Period Type, user can specify the Period Length, which can be a day, a week or a month. Periods are non-overlapping and fixed to the calendar start and end dates. Compliance is calculated at the end of the time period. An example of where the Calendar period makes sense is when the company wants to calculate SLO compliance one quarter at a time.
-
Rolling Period, when selected as the Period Type, user can specify the number of days for the Period Length, like, 30 days. They don’t have fixed start and end dates. With a rolling time period, you get the last 30 day measure of compliance, each day, rather than one per month. However, services can hover between compliance and non-compliance as the SLO status changes daily.
-
False Positives are those incidents that were marked initially as affecting an SLO (and hence be considered for error budget calculations) but after further analysis, they were deemed not to be SLO affecting.
Getting from SLIs to SLOs
Now that we’ve defined some key concepts related to SLOs, it’s time to begin thinking about how to graft them. Developing a good understanding of how your users experience your product—and which user journeys are most critical—is the first and most important step in creating useful SLOs.
Here are a few questions you should consider:
- How are your users interacting with your application?
- What is their journey through the application?
- Which parts of your infrastructure do these journeys interact with?
- What are they expecting from your systems and what are they hoping to accomplish?
You would need to figure out how your customers interact with the product—and what path they take from when they first enter the site until they exit.
Critical user journeys are directly related to user experience, and therefore, would be important to set SLOs on.
Once you’ve gone through this exercise, you can then move on to selecting metrics—or SLIs—to quantify the level of service you are providing in these critical user journeys.
Picking good SLIs
As your infrastructure grows in complexity, it becomes more cumbersome to set external SLOs. We recommend organizing your system components into a few main categories and specifying SLIs within each of these categories.
As you start selecting SLIs, a short but important saying to keep in mind is: “All SLIs are metrics, but not all metrics make good SLIs.” This means that while you might be tracking hundreds or even thousands of metrics, you should focus on the indicators that matter most: the ones that best capture your users’ experience.
You can use the table below—which comes from Google’s SRE book—as a reference.
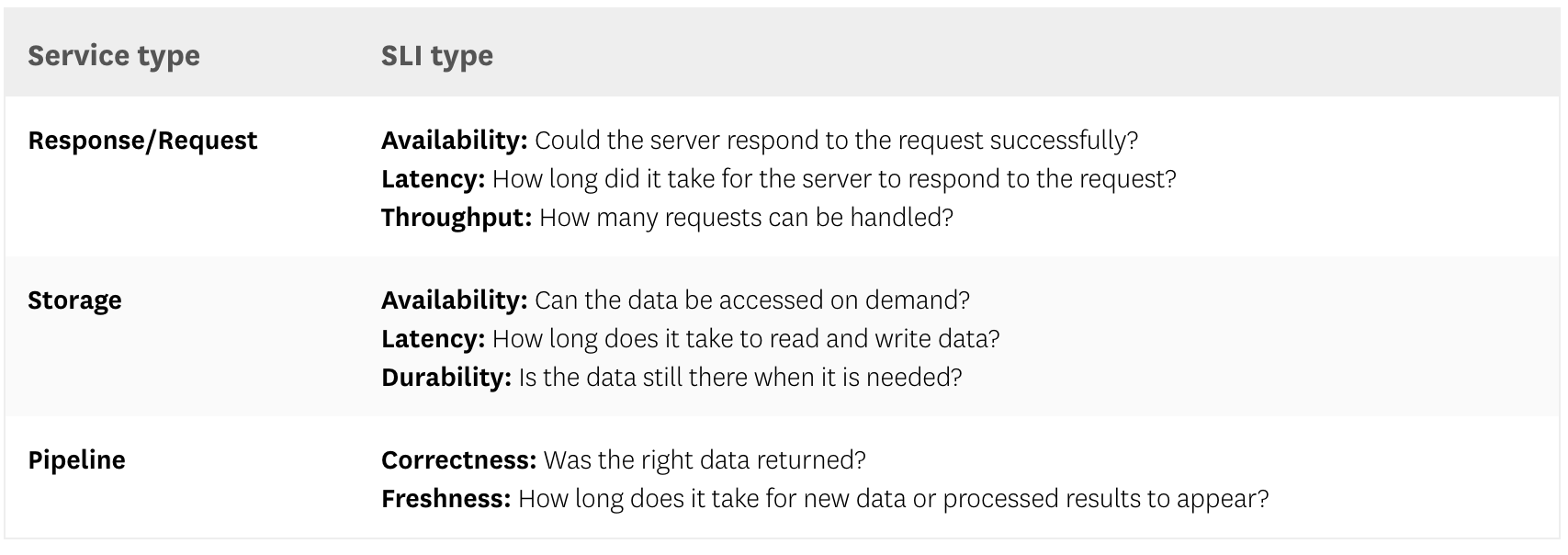
Once you have identified good SLIs, you’ll need to measure them with data from your monitoring system. Again, we recommend pulling data from the components that are in closest proximity to the user.
Finally turning SLIs into SLOs
Finally, you will need to set a target value—or range of values—for an SLI to transform it into an SLO. You should state what your best- and worst-case standard would be—and over what period of time this condition should remain valid. For example, an SLO tracking request latency might be “The latency of 99 percent of requests to the authentication service will be less than 250 ms over a 30-day period.”
As you start to create SLOs, you should keep the following points in mind.
Be realistic
And as a general rule of thumb, you should keep your SLOs slightly stricter than what you detail in your SLAs. It’s always better to err on the side of caution to ensure you are meeting your SLAs rather than consistently under-delivering.
Experiment away
There is no hard-and-fast rule for perfecting SLOs. Each organization’s SLOs will differ depending on the nature of the product, the priorities of the teams that manage them, and the expectations of the end users. Remember that you can always continue to refine your targets until you find the most optimal values.
Don’t overcomplicate it
Last but not least, resist the temptation to set too many SLOs or to overcomplicate your SLI aggregations when defining your SLO targets.
In general, you should restrict your SLOs and SLIs to only ones that are absolutely critical to your end user experience. This helps cut through the noise so you can focus on what’s truly important.
How to Define SLO of a Service?
We will discuss the step-by-step approach to defining service level objectives. There are no hard and fast rules concerning the order of the steps. Some companies start by defining user journeys and formulating the SLO accordingly, whereas others start with metrics and hypothesize user journeys later to improve and refine an existing SLO.
- Define user journey with the product team
- Identify the key services that are on the user journey and select the best SLI type
- Define SLI
- Define SLO
- Create an error budget policy
- Monitor and report on the SLO
- Periodically re-evaluate the SLO and make changes as needed
How often will my SLOs change?
If this is your first time implementing SLOs, know that they are meant to be evolutionary.
The first step is agreeing on the need for an SLO and just getting started. You don’t have to focus on getting it right the first time. It’s natural to change your SLIs and SLOs as you start measuring them and start understanding the reliability of your services better.
The Google SRE book has a fantastic read that can help you understand how to continuously improve your SLO targets.